From someone working inside Trust and Safety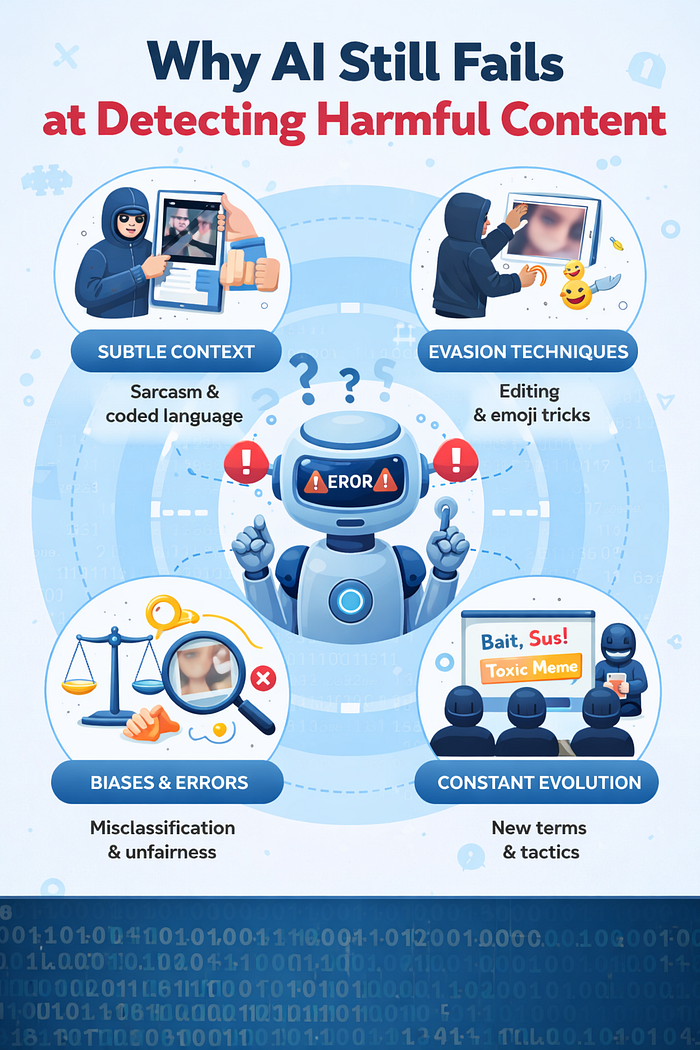
I work with AI moderation systems every day.
I see the dashboards. The confidence scores. The automated removals. The appeals that follow.
And here’s the truth that doesn’t make it into product demos:
AI is powerful.
But it still fails at detecting harmful content in ways that matter.
Not because engineers are careless.
Not because the models are “bad.”
But because harm online is more complex than pattern recognition.
Let me explain what that looks like from inside Trust and Safety.
1. Harm Evolves Faster Than Models Do
AI systems are trained on historical data.
But harmful behavior online evolves constantly.
New slang replaces banned words.
Dog whistles replace explicit hate speech.
Images are slightly altered to avoid detection.
Misinformation is framed as “just asking questions.”
By the time a pattern becomes obvious enough to train on, bad actors have often moved on.
From an operational perspective, we’re always responding to yesterday’s tactics while new ones are emerging in real time.
AI learns from the past. Harm adapts in the present.
2. Context Lives Outside the Frame
AI evaluates what it can see: text, audio, images, metadata.
But harm often depends on context that exists outside that single piece of content.
A sentence alone may look harmless.
In a coordinated harassment campaign, it’s a signal.
A video clip might appear neutral.
In the context of an ongoing conflict, it’s inflammatory.
Moderators often rely on behavioral patterns, historical account activity, cultural knowledge, and external context.
AI, unless heavily engineered for it, evaluates fragments.
And fragments can be misleading.
3. Intent Is Harder Than Keywords
Harm is not always about explicit language.
Sometimes it’s about:
- Implied threats
- Subtle incitement
- Targeted dog whistles
- Manipulative framing
- Emotional provocation
AI systems perform well when violations are clear and repeatable.
They struggle when harm hides behind plausible deniability.
From my experience, some of the most damaging content technically avoids violating obvious rules. It pushes boundaries without crossing clear lines.
That’s where AI detection weakens.
4. False Negatives Don’t Make Headlines
When AI incorrectly removes harmless content, people notice. Appeals increase. Public complaints rise.
But when AI fails to detect harmful content, the impact is quieter at first.
A post spreads.
A harmful narrative gains traction.
A harassment thread builds momentum.
By the time it becomes visible, it may already have reached thousands.
From inside moderation, you see how small misses compound.
Even a tiny failure rate becomes significant at scale.
5. Cultural and Linguistic Nuance Is Hard to Generalize
Global platforms operate across languages, dialects, and cultural norms.
What is considered hate speech in one region may be reclaimed identity language in another. Humor in one culture may read as hostility in another.
Training models to account for this nuance is incredibly complex.
From an operational standpoint, regional enforcement often reveals gaps faster than global models can adjust.
AI performs best in structured environments. Culture is not structured.
6. Confidence Scores Create False Certainty
AI outputs probabilities.
But in practice, those probabilities are often treated as decisions.
A high-confidence “safe” classification may reduce scrutiny. A borderline case may not be escalated.
The system doesn’t announce its uncertainty emotionally. It outputs a number.
And numbers feel authoritative.
But probability is not understanding.
Inside Trust and Safety, we see how misplaced confidence can allow subtle harm to pass through.
7. The Core Limitation: AI Doesn’t Understand Human Motivation
At its core, harmful content is rooted in human intent.
Revenge. Ideology. Manipulation. Exploitation. Profit.
AI can detect patterns associated with those behaviors.
It cannot understand why they are happening.
And without understanding motivation, detecting evolving forms of harm becomes reactive instead of anticipatory.
Human moderators often sense shifts in tone, coordination, or escalation before systems flag them.
That intuition comes from lived exposure to behavior, not just data.
Final Thoughts
AI moderation is not ineffective. It removes massive amounts of harmful content daily. It protects users at a scale humans alone never could.
But it still fails at detecting harmful content because harm is dynamic, contextual, and intentional.
AI sees signals.
Humans interpret meaning.
From where I sit in Trust and Safety, the future isn’t about replacing one with the other.
It’s about recognizing the limits of automation and designing systems where AI handles scale, while humans handle judgment.
Because harmful content isn’t just a technical problem.
It’s a human one.